May 21, 2025 · 10 min read
Accurate Transcription in Local Languages: Key Considerations
In recent years, AI has taken off. Since the introduction of ChatGPT, giants such as Google, OpenAI and Anthropic have been fighting to position themselves as AI-first as possible. First and foremost, they are pushing their language models, but AI is more than just a chatbot. Although it may be somewhat underexposed in the hype, great strides have also been made in other domains, such as image recognition, text-to-speech and video generation. In this piece, I will specifically discuss the developments in transcription models, often referred to as speech-to-text (STT) or Automatic Speech Recognition (ASR). Because although there has been a lot of progress in this field, the Anglo-Saxon focus of the mainly American players active in this field leaves room for improvement in the European market. Think of accurate transcription of smaller languages and dialects, privacy-friendly data processing and specialized editing tools.

The origin of my passion for transcription
Before we continue, I would like to tell you why this subject fascinates me immensely. During my studies in Business and Information Systems Engineering at KU Leuven, I noticed that many friends in social sciences had to conduct a lot of interviews for their thesis. These then had to be typed out one by one and analyzed: a long-winded and mind-numbing process that often took away time from the actual research. Surely there had to be a more efficient way? I had built myself a small application that automatically generated lyric videos for my Dutch songs as MC Ulies. Before that, I had fine-tuned OpenAI's Whisper language model for Flemish. To help my friends, I built a small transcription application around the model and the reactions were immediately enthusiastic. After further inquiry, the quality of the transcript turned out to be much higher than the available alternatives, which made automatic transcription worthwhile for many the first time. Soon, a hundred students at KU Leuven saved 3 hours of time per hour of audio by Scribewave to have the transcription done, instead of typing it out word by word manually. But students are of course not the only audience that needs transcription. I am currently working on a PhD and as a researcher I often deal with interviews, focus groups and of course… meetings every day. Since corona, online meetings are everywhere, and here too automatic transcription comes in handy - especially if you couple it with summaries or an AI that automatically processes the transcript into professional meeting notes.

Challenges for current models
If you’ve done any surfing around looking for transcription, you’ll notice that there’s a wide variety of transcription services out there. One thing they all have in common is that most providers are based in the United States, a trend that’s also seen in other places in the technology sector. The companies behind popular language models have mountains of data, fancy buttons, and powerful servers to train new models.
Accuracy in non-English languages and dialects
But the big American models often focus mainly on English, and they ignore smaller languages like Dutch, Hungarian and Finnish. Furthermore, they are not at all concerned with local dialects, although they can differ enormously. I still remember how my Dutch teacher in high school illustrated the Flemish linguistic diversity with “'t es wet” (it is white in West Flemish) and “et ès zwèt” (it is black in Antwerp: same sound, opposite meaning!). The same idea applies to French, German, Italian and Portuguese.
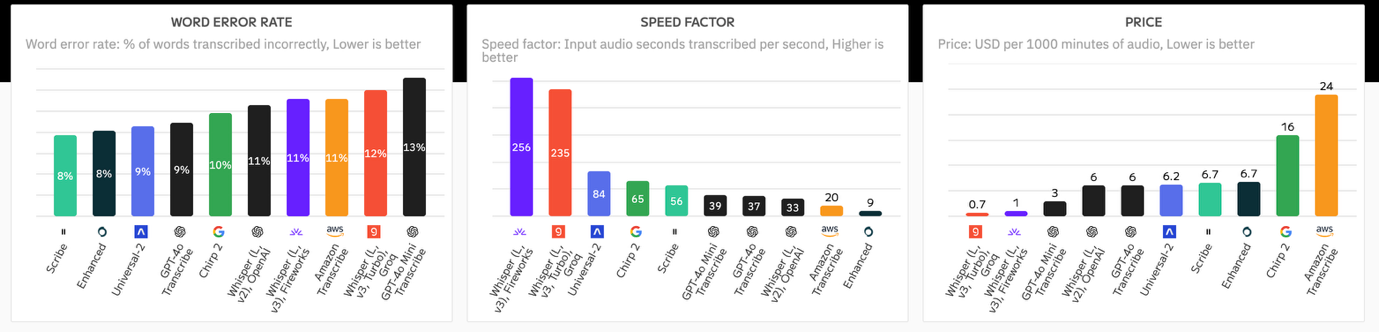
Now it's not all doom and gloom: the market is moving fast and popular models like Whisper are already supporting non-English languages quite well. There is a proliferation of TTS providers, from Assembly to Deepgram. Each comes with its own strengths and weaknesses, and almost every week a new model is released that performs better in one language and worse in another. This makes it difficult to keep track. I noticed this myself when I wanted to test the pros and cons of my own models against other players: the moment I had run my test, a new model was available, and I had to start over. Sometimes there are difficult trade-offs: Whisper V3 is more accurate than Whisper V2 for most languages, but then suffers from hallucinations, the “making up” of text that was never spoken. To keep track, I have given such trade-offs a score and set up a professional benchmarking pipeline that constantly monitors the accuracy of 11 models on 99 languages. The interesting thing is that it is automatically linked to my speech-to-text service. That is, when you have a file transcribed by Scribewave, in the background it automatically selects the most accurate model for that language from a set of all available models on the market, including specialized, fine-tuned models for dialects.
Jargon, proper names and self-learning mechanism
In addition to dialects, there is also jargon; specialized technical terms that may not be known to the ASR model. With many models, you see that they struggle in a medical or financial context, because there are so many “exotic terms” that they have not encountered during their training phase. Proper names can also sometimes be challenging, so that a model quickly makes mistakes like typing out a name phonetically as “Lowieze Dubwa” instead of “Louise Dubois”. Although this problem cannot be solved completely, custom local language models such as those from Scribewave come in handy here too. In addition, I have developed a self-learning mechanism that builds a unique personal language model based on the edits you have made to previous transcripts. In this way, the model becomes better and better for your exact use case.
Different languages mixed together (context switching)
I am Belgian and I often work in Brussels in an international research group. In one day, I regularly hear more than five different languages. Often in meetings or interviews different languages are spoken together. Think of my sister who is a lawyer and often has to lead conversations in a mix of English, French and Farsi. Many models, such as Whisper, tend to choose one main language and automatically translate all transcribed text into that main language. This can be useful, but often it is relevant to leave everything in the original language. That is why I have also developed a unique “multi-language” language model, which effortlessly switches between different languages in the same recording. After the transcript is created, you can of course still translate into any chosen language thanks to a built-in automatic translation with Deepl.
Verbatim vs Readability
Transcription is not a “one-size-fits-all” business. Nowhere is this more evident than in the debate over verbatim vs. readable output. Depending on your specific situation, you may be looking for an exact, word-for-word transcript, including all the filler words, stutters, coughs, and hesitations. We call this a “verbatim” transcript, and it’s often used by researchers, lawyers, and HR professionals during interviews. But in other industries, the “spirit of the text” is more important. Meeting transcripts are more readable when written in clear, complete sentences, and subtitles often convert interlocutory speech to standard language. It’s not black and white either: catch-all speech can be very useful for video editors and podcasters, for example, as it allows them to automatically remove all the stutters from content. I like to offer this flexibility with Scribewave: by default, speech is converted verbatim to text, exactly as it was said. This verbatim transcript can then be processed into a smooth text by the AI function “enhance transcript”. This approach ensures that you can easily switch between the original and the cleaned-up version.
Speaker Diarization
In almost every situation, you want a clear distinction between who is saying what. In interviews, the interviewer's questions need to be separated from the interviewee's, in meetings you want to know who has been assigned which tasks. The more accurately an AI model can distinguish between different voices, the better. Most commercial language models offer this out-of-the-box. For open-source models like Whisper, you have to configure this yourself, for example with PyAnnote. The term “speaker recognition” is a bit misleading: in essence, it is about recognizing different voices, but that does not mean that every speaker is immediately labeled with the correct name. Typically, you get a result in the form "Speaker 1”, “Speaker 2”, … To efficiently label the different speakers with the correct names, you need an interface that can update the labels in batch. This is standard in transcription clients like Scribewave. But we want to take it a step further: what if the system can remember which speaker belongs to which voice? That way, you only must label the corresponding voice with the correct name once, and this happens automatically for every subsequent recording you upload. This is a feature that we are currently testing and will roll out to Scribewave soon.

Data, privacy and training
In the AI economy, the well-known adage “data is the new gold” is more true than ever. Developers of these AI models often sell their tokens below cost price, because it helps them collect huge amounts of data from users, which is then used to train new models. This data almost always has to be labeled by people, which means that your private recordings can easily be listened to by an OpenAI contractor. That is why it is always important to look at the privacy guarantees that a transcription service offers. Is the data processed on European servers? Is your data used for training? The safest thing to do is to use a Data Privacy Agreement (DPA) to sign with your provider. As a European company, Scribewave pays extra attention to privacy and secure data processing. By default, data is stored on European servers, and data from paying users is not used for training. Of course, we also offer enterprise customers the option of drawing up a custom DPA, to guarantee that you as an uploader always remain the owner of your data under your terms, and that it is deleted from our servers without leaving any traces when necessary.
Editing and Exporting: From Text to Subtitles
It’s nice to have a robot automatically convert your transcript to text. But with a lot of text on its own, you can’t do much. Often you want to be able to efficiently review the result, edit it where necessary and download it for further use. To enable clear formatting of speakers and time codes, the system needs to keep track of which word was said at which exact moment, and who said it. Scribewave has all of this under the hood, meaning you can edit efficiently and move through the transcript quickly. Speech and text are linked, so everything scrolls automatically along with the recording.
Happy with the result? Then you can download it as a Word document, export it to Google Docs, or make subtitles from it. Many more file formats are available of course, each with numerous options, such as the maximum number of characters (CPL) for subtitles.
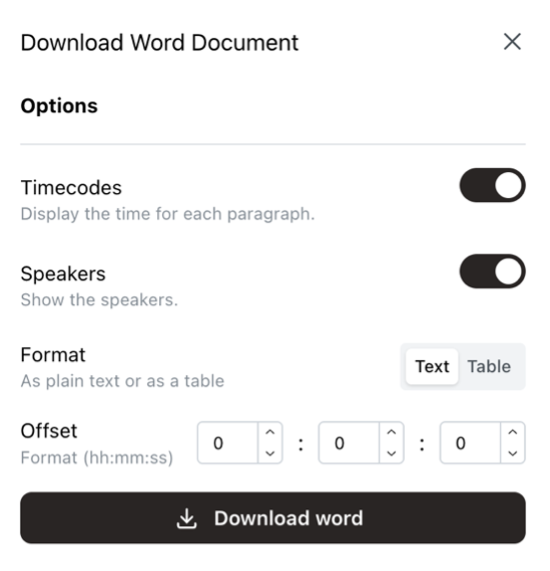
File size and duration
Some tools and APIs come with serious limitations. For example, OpenAI’s Whisper API is limited to 20MB files, which is very small, especially if you’re uploading video. To get around these limits, you can use batching strategies, but these often make it difficult to consistently tag speakers, requiring two parallel processes. Some APIs only support certain file formats, requiring you to convert your files to mp3 or mp4 to use them. You can also skip the compression and conversion process altogether and take advantage of unlimited uploads on Scribewave. I was so frustrated by the conversion process and file size limits on other transcription services that I built a universal upload and processing mechanism that supports all audio and video files up to 5GB and 10 hours in length.
Conclusion: Transcription as a lever for inclusive AI
Transcription may seem like a niche technical domain, but I believe it is a crucial link in the larger AI chain. Spoken language is the basis of human communication, and succeeding in converting that communication into text accurately, efficiently and linguistically aware opens the door to better searchability, accessibility, analysis and interaction with AI systems. Local languages and dialects deserve a full place in this, as do the people who speak them. My mission with Scribewave is not just to make transcription accessible to everyone, but above all to make it smarter, more human, and better attuned to the realities of users outside the Anglo-Saxon bubble. Whether you’re working on a PhD, a documentary, a meeting, or a multilingual lawsuit; your words matter. And it’s time for your automatic transcription tool to reflect that.
About the author
Ulysse Maes
In a world where Ulysse can't out-flex The Rock or out-charm Timothée Chalamet, he triumphs as the mastermind behind Scribewave, fiercely defending his throne as the king of nerds in beautiful Antwerp, Belgium.
Related articles
Discover more articles about transcription, subtitling, and translation

