21 mai 2025 · 10 min read
Transcription précise en langues locales: à quoi faut-il faire attention?
Ces dernières années, l'IA a pris son essor. Depuis l'introduction de ChatGPT, des géants comme Google, OpenAI et Anthropic se font concurrence pour se positionner comme étant les premiers en matière d'IA. Tout d'abord, ils ont mis en avant leurs modèles de langage pour cela, mais l'IA est plus que le chatbot. Même si cela peut être quelque peu négligé dans la bataille médiatique, les progrès ont également été réalisés dans d'autres domaines, tels que la reconnaissance d'images, la synthèse vocale et la génération de vidéos. Dans cet article, je discute spécifiquement des développements dans les modèles de transcription, souvent appelés speech-to-text (STT) ou Reconnaissance automatique de la parole (ASR). Même si de nombreux progrès ont été réalisés dans ce domaine, la focalisation anglo-saxonne des acteurs majoritairement américains actifs dans ce domaine laisse une marge de progression sur le marché européen. Tout d'abord, pensez à une transcription précise des langues et dialectes plus petits, à un traitement des données respectueux de la vie privée et à des outils d'édition spécialisés.

L'origine de ma passion pour la transcription
Avant d'aller plus loin, laissez-moi vous dire pourquoi ce sujet me fascine tant. Au cours de mes études en ingénierie commerciale en informatique politique à la KU Leuven, j'ai remarqué que de nombreux amis en sciences sociales devaient mener de nombreux entretiens pour leur thèse. Il fallait ensuite les transcrire un par un et les analyser : un processus long et fastidieux qui prenait souvent du temps sur la recherche elle-même. Il devait sûrement y avoir un moyen plus efficace de faire cela? J'avais construit moi-même une petite application qui générait automatiquement des vidéos de paroles pour mes chansons néerlandaises comme MC Ulies. Avant cela, j'avais peaufiné le modèle de langage Whisper d'OpenAI en flamand. Pour servir mes amis, j'ai construit une petite application de transcription autour du modèle et la réponse a été immédiatement enthousiaste. Après une enquête plus approfondie, la qualité de la transcription s'est avérée bien supérieure à celle des alternatives disponibles, ce qui rend la transcription automatique intéressante pour beaucoup la première fois. Bientôt, une centaine d'étudiants de la KU Leuven ont économisé 3 heures de temps par heure d'audio en Scribewave faire effectuer la transcription, au lieu de la taper manuellement mot par mot. Mais les étudiants ne sont bien sûr pas le seul public qui a besoin d'une transcription. Je travaille actuellement sur un doctorat et en tant que chercheur, je suis quotidiennement en contact avec des entretiens, des groupes de discussion et bien sûr… des réunions. Depuis la COVID-19, les réunions en ligne sont devenues omniprésentes, et là aussi, la transcription automatique s'avère utile, surtout si vous la liez à des résumés ou à une IA qui traite automatiquement la transcription en notes de réunion professionnelles.

Défis pour les modèles actuels
Si vous avez fait des recherches sur Internet à la recherche d'une transcription, vous remarquerez qu'il existe une grande variété de services de transcription. Un dénominateur commun est que la majorité des fournisseurs viennent des États-Unis, une tendance qui se produit à plusieurs endroits dans le secteur technologique. Les entreprises à l’origine des modèles linguistiques populaires disposent de montagnes de données, de boutons sophistiqués et de serveurs puissants pour former de nouveaux modèles.
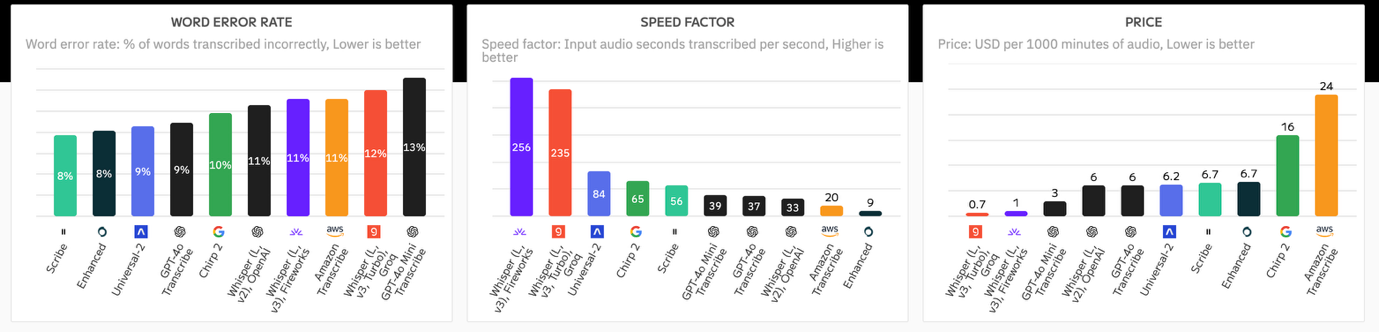
Précision dans les langues et dialectes non anglais
Mais les grands modèles américains se concentrent souvent principalement sur l'anglais, et ignorent les langues plus petites comme le néerlandais, le hongrois et le finnois. De plus, ils ne se préoccupent pas du tout des dialectes locaux, même s'ils peuvent différer énormément. Je me souviens encore bien comment mon professeur de néerlandais au lycée illustrait la diversité de la langue flamande avec “'t es wet” (c'est blanc en flamand occidental) et “et ès zwèt” (c'est noir à Anvers: même son, sens opposé !). La même idée s'applique au français, à l'allemand, à l'italien et au portugais.
Mais tout n’est pas si sombre: le marché évolue rapidement et des modèles populaires comme Whisper prennent déjà très bien en charge les langues autres que l’anglais. Il existe une prolifération de fournisseurs de TTS, de Assembly à Deepgram. Chacun d'entre eux présente ses propres forces et faiblesses, et presque chaque semaine, un nouveau modèle est publié, plus performant dans une langue et moins performant dans une autre. Cela rend difficile de garder une vue d’ensemble. J'ai moi-même remarqué cela lorsque j'ai voulu tester les avantages et les inconvénients de mes propres modèles contre d'autres joueurs : dès que j'avais terminé mon test, un nouveau modèle était disponible et je pouvais recommencer. Parfois, il y a des compromis délicats: Whisper V3 est plus précis que Whisper V2 pour la plupart des langues, mais il souffre d'hallucinations, de “creation” de texte qui n'a jamais été prononcé. Pour garder une trace, j'ai évalué ces compromis et mis en place un pipeline d'analyse comparative professionnel qui surveille en permanence la précision de 11 modèles sur 99 langues. Ce qui est intéressant, c’est qu’il est automatiquement lié à mon service de conversion de la parole en texte. Autrement dit, lorsque vous avez un fichier transcrit par Scribewave, en arrière-plan, il sélectionne automatiquement le modèle le plus précis pour cette langue parmi un ensemble de tous les modèles disponibles sur le marché, y compris des modèles spécialisés et affinés pour les dialectes.
Jargon, noms propres et mécanisme d'auto-apprentissage
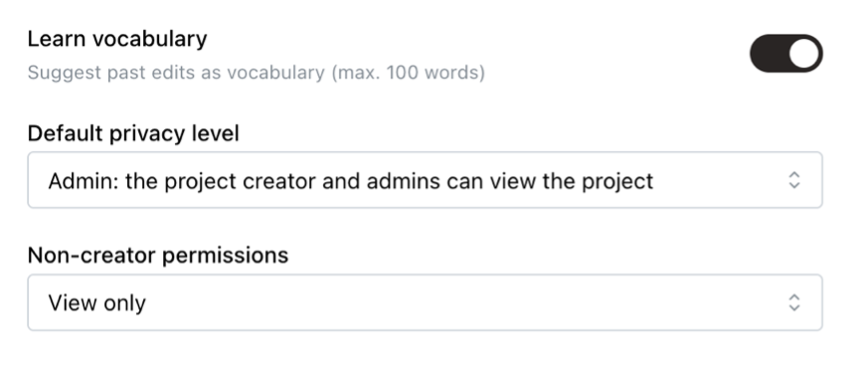
Outre les dialectes, il existe également le jargon; termes techniques spécialisés qui peuvent ne pas être connus par le modèle ASR. Avec de nombreux modèles, vous voyez qu’ils ont des difficultés dans un contexte médical ou financier parce qu’il y a tellement de “termes exotiques” impliqués qu’ils n’ont pas rencontrés pendant leur phase de formation. Même les noms propres peuvent parfois être difficiles à trouver, de sorte qu'un modèle peut rapidement se retrouver avec des noms comme “Lowieze Dubwa” au lieu de “Louise Dubois”. Bien que ce problème ne puisse pas être résolu complètement, les modèles de langage personnalisés tels que celui de Scribewave s'avèrent également utiles ici. De plus, j’ai développé un mécanisme d’apprentissage automatique qui construit un modèle de langage personnel unique basé sur les modifications que vous avez apportées aux transcriptions précédentes. De cette façon, le modèle devient de plus en plus adapté à votre cas d’utilisation exact.
Différentes langues mélangées ensemble (commutation de contexte)
Je suis belge et je travaille souvent à Bruxelles dans un groupe de recherche international. En une journée, j’entends régulièrement plus de cinq langues différentes. Souvent, des langues différentes sont parlées de manière interchangeable lors de réunions ou d’entretiens. Pensez simplement à ma sœur qui est avocate et qui doit souvent mener des conversations dans un mélange d’anglais, de français et de farsi. De nombreux modèles tendance à choisir une langue principale et à traduire automatiquement tout le texte transcrit dans cette langue principale. Cela peut être utile, mais il est souvent pertinent de tout laisser dans la langue d’origine. C'est pourquoi j'ai également développé un modèle de langage “multilingue” unique, qui permet de basculer sans effort entre différentes langues dans le même enregistrement. Une fois la transcription créée, vous pouvez bien sûr toujours la traduire dans la langue de votre choix grâce à une traduction automatique intégrée avec Deepl.
Verbatim vs Lisibilité
La transcription n’est pas une activité “universelle”. Nulle part cela n’est plus évident que dans le débat entre les résultats textuels et les résultats lisibles. Selon votre situation spécifique, vous rechercherez peut-être une transcription exacte, mot à mot, incluant tous les mots de remplissage, les bégaiements, la toux et les hésitations. Nous appelons cela une transcription “verbatim” et elle est souvent utilisée par les chercheurs, les avocats et les professionnels des RH lors des entretiens. Mais dans d’autres secteurs, c’est “l’esprit du texte” qui est plus souvent pris en compte. Les transcriptions de réunions sont plus lisibles lorsqu'elles sont rédigées en phrases claires et complètes, et les sous-titres convertissent souvent l'interlangue en langage standard. Ce n'est pas non plus noir ou blanc : identifier les mots vides peut être très intéressant pour les monteurs vidéo et les créateurs de podcasts, par exemple, car cela leur permet de supprimer automatiquement tout problème de contenu. Avec Scribewave, j'aime offrir cette flexibilité: par défaut, la parole est convertie mot pour mot en texte, exactement comme elle a été dite. Vous pouvez ensuite faire transformer cette transcription littérale en un texte fluide à l'aide de la fonction d'IA “améliorer la transcription”. Cette approche garantit que vous pouvez facilement basculer entre la version originale et la version nettoyée.
Journalisation des intervenants
Dans presque toutes les situations, vous souhaitez qu’une distinction claire soit faite entre qui dit quoi. Lors des entretiens, les questions de l'intervieweur doivent être séparées de celles de la personne interrogée. Lors des réunions, vous souhaitez savoir à qui ont été assignées quelles tâches. Plus un modèle d’IA peut distinguer avec précision différentes voix, mieux c’est. La plupart des modèles de langage commerciaux offrent cette fonctionnalité prête à l'emploi. Pour les modèles open source comme Whisper, vous devez toujours le configurer vous-même, par exemple avec PyAnnote. Le terme “reconnaissance du locuteur” est un peu trompeur : il s’agit essentiellement de reconnaître différentes voix, mais cela ne signifie pas que chaque locuteur est immédiatement étiqueté avec le nom correct. En général, vous obtiendrez un résultat sous la forme “Speaker 1”, “Speaker 2”, … Pour étiqueter efficacement les différents speakers avec les noms corrects, vous avez besoin d'une interface capable de mettre à jour les étiquettes par lots. C'est la norme dans les clients de transcription comme Scribewave. Mais nous voulons aller plus loin : et si le système pouvait se souvenir à quel locuteur appartient quelle voix ? De cette façon, vous n'aurez qu'à saisir une seule fois le nom correct de la voix correspondante, et cela se produira automatiquement pour chaque enregistrement ultérieur que vous téléchargerez. Il s’agit d’une fonctionnalité que nous testons actuellement et que nous déploierons bientôt sur Scribewave.

Données, confidentialité et formation
Dans l’économie de l’IA, l’adage bien connu “les données sont le nouvel or” s’applique plus que jamais. Les développeurs de ces modèles d’IA vendent souvent leurs jetons à un prix inférieur à leur prix de revient, car cela les aide à collecter des quantités massives de données auprès des utilisateurs, qui sont ensuite utilisées pour former de nouveaux modèles. Ces données doivent presque toujours être étiquetées par des humains, ce qui signifie que vos enregistrements privés pourraient facilement être écoutés par un sous-traitant d'OpenAI. C’est pourquoi il est toujours important d’examiner les garanties de confidentialité qu’offre un service de transcription. Les données sont-elles traitées sur des serveurs européens ? Vos données seront-elles utilisées à des fins de formation ? La chose la plus sûre à faire est de Accord de confidentialité des données (DPA) à signer avec votre fournisseur. En tant qu'entreprise européenne, Scribewave accorde une attention particulière à la confidentialité et au traitement sécurisé des données. Par défaut, les données sont stockées sur des serveurs européens et les données des utilisateurs payants ne sont pas utilisées pour la formation. Bien entendu, nous offrons également aux clients professionnels la possibilité de configurer un DPA personnalisé, afin de garantir que vous, en tant que téléchargeur, restez toujours propriétaire de vos données selon vos conditions, et qu'elles sont supprimées de nos serveurs sans laisser de traces si nécessaire.
Édition et exportation : du texte aux sous-titres
C'est bien qu'un robot convertisse automatiquement votre transcription en texte. Mais avec beaucoup de texte à lui seul, vous ne pouvez pas faire grand-chose. Souvent, vous souhaitez pouvoir examiner efficacement le résultat, le modifier si nécessaire et le télécharger pour une utilisation ultérieure. Pour permettre un formatage clair des locuteurs et des codes temporels, le système doit garder une trace en arrière-plan du mot prononcé à quel moment précis et de la personne qui l'a prononcé. Scribewave a tout cela sous le capot, ce qui signifie que vous pouvez éditer efficacement et parcourir votre transcription rapidement. La parole et le texte sont liés, de sorte que tout défile automatiquement avec l'enregistrement.
Satisfait du résultat ? Vous pouvez ensuite le télécharger sous forme de document Word, l'exporter vers Google Docs ou créer des sous-titres. Bien entendu, de nombreux autres formats de fichiers sont disponibles, chacun avec de nombreuses options, telles que la limite maximale de caractères (CPL) pour les sous-titres.
Taille et durée du fichier
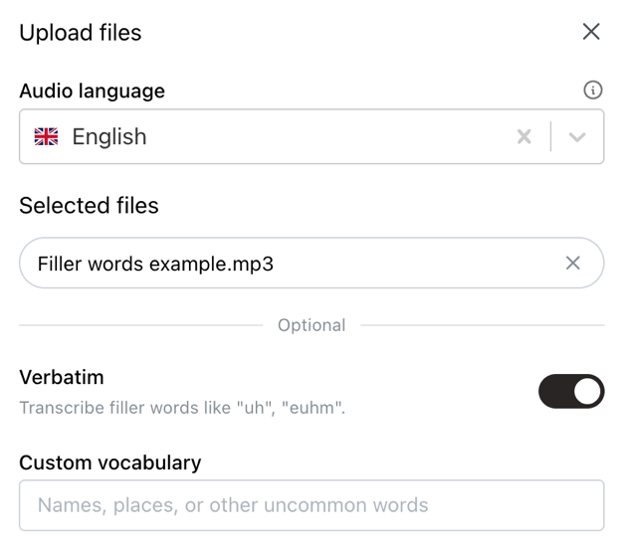
Certains outils et API présentent de sérieuses limitations. Par exemple, l'API Whisper d'OpenAI est limitée aux fichiers de 20 Mo, ce qui est très petit, surtout si vous téléchargez une vidéo. Pour contourner ces limites, vous pouvez utiliser des stratégies de traitement par lots, mais celles-ci rendent souvent difficile l'étiquetage cohérent des haut-parleurs, nécessitant deux processus parallèles. Certaines API ne prennent en charge que certains formats de fichiers, vous obligeant à convertir vos fichiers en mp3 ou mp4 pour pouvoir les utiliser. Vous pouvez également simplement ignorer la compression et la conversion et profiter de téléchargements illimités sur Scribewave. J'étais tellement frustré par le processus de conversion et les limites de fichiers sur d'autres services de transcription que j'ai intégré un mécanisme de téléchargement et de traitement universel qui prend en charge tous les fichiers audio et vidéo jusqu'à 5 Go et 10 heures de durée.
Conclusion : La transcription comme levier pour une IA inclusive
La transcription peut sembler être un domaine technique de niche, mais je pense qu’il s’agit d’un maillon crucial de la chaîne plus large de l’IA. La langue parlée est le fondement de la communication humaine, et la capacité à convertir cette communication en texte avec précision, efficacité et en tenant compte de la langue ouvre la porte à une plus grande capacité de recherche, d’accessibilité, d’analyse et d’interaction avec les systèmes d’IA. Les langues et dialectes locaux méritent une place à part entière, tout comme les peuples qui les parlent. Ma mission avec Scribewave Il ne s’agit donc pas seulement de rendre la transcription accessible à tous, mais surtout de la rendre plus intelligente, plus humaine et mieux adaptée à la réalité des utilisateurs hors de la bulle anglo-saxonne. Que vous travailliez sur un doctorat, un documentaire, une réunion ou une affaire juridique multilingue ; Vos mots comptent. Et il est temps que votre outil de transcription automatique reflète également cela.
À propos de l'auteur
Ulysse Maes
Dans un monde où Ulysse ne peut rivaliser ni avec la musculature de The Rock, ni avec le charme de Timothée Chalamet, il triomphe en tant que cerveau derrière Scribewave, défendant farouchement son trône de roi des nerds dans la magnifique ville d'Anvers, en Belgique.
Articles connexes
Découvrir plus

