21 mei 2025 · 10 min read
Nauwkeurige transcriptie in lokale talen: Waar moet je op letten?
De laatste jaren heeft AI een enorme vlucht genomen. Sinds de introductie van ChatGPT, strijden giganten als Google, OpenAI en Anthropic om zich zoveel mogelijk AI-first te positioneren. In eerste plaats schuiven ze daarvoor hun taalmodellen naar voor, maar AI is meer dan een chatbot. Hoewel het misschien wat onderbelicht blijft in de hype, zijn er ook grote stappen gezet op andere domeinen, zoals beeldherkenning, text-to-speech en videogeneratie. In dit stuk bespreek ik specifiek de ontwikkelingen in transcriptiemodellen, vaak aangeduid met speech-to-text (STT) of Automatic Speech Recognition (ASR). Want hoewel er ook op dit veld veel progressie is gemaakt, laat de Angelsaksische focus van de voornamelijk Amerikaanse spelers die in dit veld actief zijn ruimte voor verbetering op de Europese markt. Denk dan in de eerste plaats aan accurate transcriptie van kleinere talen en dialecten, privacy-vriendelijke gegevensverwerking en gespecialiseerde editing tools.

De oorsprong van mijn passie voor transcriptie
Vooraleer we verder gaan, laat ik je graag nog weten waarom dit onderwerp me mateloos fascineert. Tijdens mijn studies Handelsingenieur Beleidsinformatica aan KU Leuven, merkte ik op dat veel vrienden in sociale wetenschappen een heleboel interviews moesten afnemen voor hun thesis. Die moesten vervolgens één voor één uitgetypt worden en geanalyseerd: een langdradig en geestdodend proces dat vaak tijd wegnam om aan het echte onderzoek te besteden. Dit moest toch efficiënter kunnen? Ik had voor mezelf een kleine applicatie gebouwd die automatisch lyric video’s genereerde voor mijn Nederlandstalige liedjes als MC Ulies. Daarvoor had ik het Whisper taalmodel van OpenAI gefinetuned op het Vlaams. Om mijn vrienden van dienst te zijn, bouwde ik een kleine transcriptie-applicatie rond het model en de reacties waren meteen enthousiast. Na verdere navraag bleek de kwaliteit van het transcript veel hoger te liggen dan de beschikbare alternatieven, wat automatische transcriptie voor velen de eerste keer de moeite waard maakte. Al snel bespaarden een honderdtal studenten aan KU Leuven 3 uur tijd per uur audio uit door Scribewave de transcriptie te laten doen, in plaats van dit woord voor woord manueel uit te typen. Maar studenten zijn uiteraard niet het enige publiek dat transcriptie nodig heeft. Ik werk momenteel aan een doctoraat en als onderzoeker kom ik elke dag in contact met interviews, focusgroepen en natuurlijk…meetings. Sinds corona zijn online meetings overal, en ook hier komt automatische transcriptie weer goed van pas – zeker als je het koppelt aan samenvattingen of een AI die het transcript automatisch verwerkt naar professionele meeting notes.

Uitdagingen voor huidige modellen
Als je al wat hebt rondgesurft op zoek naar transcriptie, dan valt je zeker op dat er een grote variëteit bestaat van transcriptiediensten. Eén gemeenschappelijke deler is dat het gros van de aanbieders uit de Verenigde Staten komt, een trend die zich op wel meerdere plekken in de technologiesector voordoet. De bedrijven achter de populaire taalmodellen beschikken dan ook over bergen data, knappe knoppen en stevige servers om nieuwe modellen te trainen.
Accuratie in niet-Engelse talen en dialecten
Maar de grote Amerikaanse modellen focussen vaak voornamelijk op het Engels, en kleinere talen zoals Nederlands, Hongaars en Fins laten ze links liggen. Verder zijn ze hoegenaamd niet bezig met lokale dialecten, hoewel die enorm kunnen verschillen. Ik herinner me nog goed hoe mijn leraar Nederlands in het middelbaar de Vlaamse taaldiversiteit illustreerde met “’t es wet” (het is wit in het West-Vlaams) en “et ès zwèt” (het is zwart in het Antwerps: zelfde klank, tegenovergestelde betekenis!). Hetzelfde idee geldt voor het Frans, Duits, Italiaans en Portugees.
Nu is het niet allemaal kommer en kwel: de markt gaat snel vooruit en intussen ondersteunen populaire modellen als Whisper niet-Engelse talen ook al behoorlijk. Er is een wildgroei aan TTS providers, van Assembly tot Deepgram. Elks komen ze met hun eigen sterktes en zwaktes, en bijna wekelijks wordt er wel een nieuw model uitgebracht dat voor de ene taal beter, en de andere taal slechter presteert. Dit maakt het moeilijk om het overzicht te houden. Ik merkte dit ook zelf toen ik de voor- en nadelen van mijn eigen modellen wilde toetsen aan andere spelers: op het moment dat ik mijn test had uitgevoerd, was er weer een nieuw model beschikbaar en kon ik opnieuw beginnen. Soms zijn er lastige trade-offs: Whisper V3 is voor de meeste talen accurater dan Whisper V2, maar heeft dan weer last van hallucinaties, het “verzinnen” van tekst die nooit is gezegd. Om het overzicht te bewaren, heb ik zulke trade-offs een score gegeven en een professionele benchmarking-pipeline opgezet, die de accuratie van 11 modellen op 99 talen constant monitort. Het interessante is dat die automatisch gekoppeld is aan mijn spraak-naar-tekst service. Dat wil zeggen: wanneer je een bestand laat transcriberen door Scribewave, wordt er op de achtergrond automatisch het meest accurate model geselecteerd voor die taal uit een set van alle beschikbare modellen op de markt, inclusief gespecialiseerde, gefinetunede modellen voor dialecten.
Jargon, eigennamen en zelflerend mechanisme
Naast dialecten is er ook nog jargon; gespecialiseerde vaktermen die mogelijks niet gekend zijn door het ASR model. Bij veel modellen zie je dat ze het moeilijk krijgen in een medische of financiële context, omdat er zoveel “exotische termen” in voorkomen die ze niet hebben gezien tijdens hun trainingsfase. Ook eigennamen kunnen soms uitdagend zijn, zodat een model al snel kemels slaat als “Lowieze Dubwa” in plaats van “Louise Dubois”. Hoewel dit probleem niet volledig op te lossen valt, komen custom taalmodellen zoals die van Scribewave ook hier weer van pas. Bovendien heb ik een zelflerend mechanisme ontwikkeld dat een uniek persoonlijk taalmodel bouwt op basis van de bewerkingen die je hebt gemaakt op eerdere transcripts. Zo wordt het model steeds beter voor jouw exacte use case.
Verschillende talen door elkaar (context switching)
Ik ben Belg en ik werk vaak in Brussel in een internationale onderzoeksgroep. Op één dag hoor ik regelmatig meer dan vijf verschillende talen. Vaak wordt er in meetings of interviews verschillende talen door elkaar gesproken. Denk maar aan mijn zus die advocaat is, en vaak gesprekken in een mix van Engels, Frans en Farsi moet leiden. Veel modellen, zoals Whisper, hebben de neiging om één hoofdtaal te kiezen en automatisch alle getranscribeerde tekst te vertalen naar die hoofdtaal. Dit kan handig zijn, maar vaak is het relevant om alles in de oorspronkelijke taal te laten. Daarom heb ik ook een uniek “multi-language” taalmodel ontwikkeld, dat moeiteloos switcht tussen verschillende talen in dezelfde opname. Nadat het transcript is gecreëerd kan je uiteraard nog steeds vertalen naar elke gekozen taal dankzij een ingebouwde automatische vertaling met Deepl.
Verbatim vs leesbaarheid
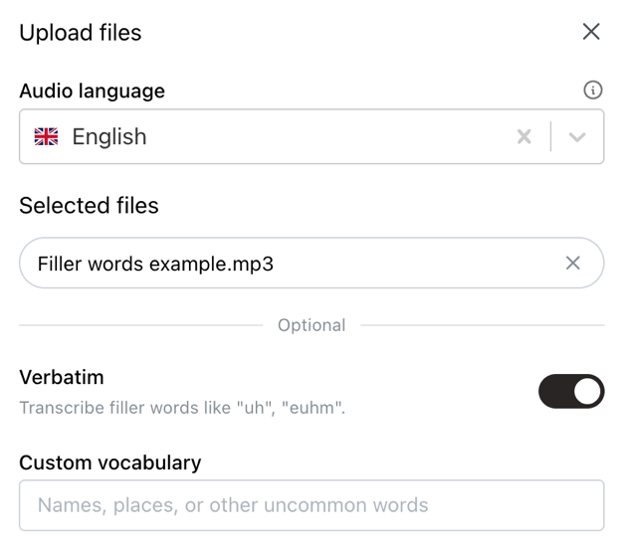
Transcriptie is geen “one-size-fits-all” business. Nergens komt dit zo duidelijk tot uiting als bij het debat over verbatim vs leesbare resultaten. Afhankelijk van je concrete situatie, ben je op zoek naar een exact, woord-voor-woord transcript, inclusief alle stopwoorden, stotteringen, kuchjes en aarzelingen. We noemen dit een “verbatim” transcript, en het wordt vaak gebruikt door onderzoekers, advocaten en HR-professionals bij interviews. Maar in andere sectoren wordt er vaker gekeken naar de “geest van de tekst”. Meeting transcripts zijn beter leesbaar wanneer die in heldere, complete zinnen zijn neergeschreven, en ondertitels converteren tussentaal regelmatig naar standaardtaal. Het is ook niet zwart-wit: het herkennen van stopwoorden kan bijvoorbeeld erg interessant zijn voor video-editors en podcastmakers, omdat ze zo automatisch alle haperingen uit content kunnen knippen. Met Scribewave biedt ik deze flexibiliteit graag aan: standaard wordt spraak verbatim omgezet naar tekst, exact zoals het is gezegd. Dit verbatim transcript kan je vervolgens tot een vlotte tekst laten verwerken door de AI-functie “enhance transcript”. Deze aanpak zorgt ervoor dat je vlot kan wisselen tussen de orinele en de opgekuiste versie.
Sprekerherkenning (speaker diarization)
In bijna elke situatie wil je dat er een duidelijk onderscheid wordt gemaakt tussen wie wat zegt. In interviews moeten de vragen van de interviewer gescheiden worden van de interviewee, in meetings wil je weten wie welke taken toebedeeld heeft gekregen. Hoe accurater een AI-model verschillende stemmen uit elkaar kan houden, hoe beter. De meeste commerciële taalmodellen bieden dit out-of-the-box aan. Voor open-source modellen zoals Whisper moet je dit zelf nog configureren, bijvoorbeeld met PyAnnote. De term “sprekerherkenning”, of “speaker recognition” in het Engels, is wat misleidend: in se gaat het hier over het herkennen van verschillende stemmen, maar dat wil nog niet zeggen dat elke spreker meteen de juiste naam gelabeld krijgt. Typisch krijg je een resultaat in de vorm "Speaker 1”, “Speaker 2”, … Om efficiënt de verschillende sprekers met de juiste namen te labelen, heb je een interface nodig die de labels in batch kan updaten. Dit zit standaard in transcriptieclients zoals Scribewave. Maar we willen nog een stapje verder gaan: wat als het systeem kan onthouden welke spreker bij welke stem hoort? Zo hoef je slechts één keer de juiste naam bij de bijhorende stem te plaatsen, en gebeurt dit automatisch bij elke volgende opname die je uploadt. Dit is een functie die we momenteel uittesten en snel in Scribewave zullen uitrollen.

Data, privacy en training
In de AI-economie geldt meer dan ooit het welbekende adagio “data is het nieuwe goud”. De ontwikkelaars van deze AI modellen verkopen hun tokens vaak onder de kostprijs, omdat het hen helpt om gigantische hoeveelheden data van gebruikers te verzamelen, die vervolgens worden gebruikt voor training van weer nieuwe modellen. Deze data moet bijna altijd gelabeld worden door mensen, wat betekent dat je private opnames zomaar door een contractor van OpenAI beluisterd kunnen worden. Daarom is het steeds belangrijk om te kijken naar de privacy-garanties die een transcriptiedienst aanbiedt. Wordt de data verwerkt op Europese servers? Worden je gegevens gebruikt voor training? Het veiligste is om een Data Privacy Agreement (DPA) te tekenen met je provider. Scribewave besteedt als Europees bedrijf extra aandacht aan privacy en veilige gegevensverwerking. Standaard wordt de data opgeslagen op Europese servers, en data van betalende gebruikers wordt niet gebruikt voor training. Uiteraard bieden we enterprise-klanten ook de mogelijkheid tot het opstellen van een custom DPA, om te garanderen dat je als uploader steeds eigenaar blijft van je data onder jouw voorwaarden, en dat deze zonder sporen achter te laten wordt verwijderd van onze servers wanneer nodig.
Bewerken en exporteren: van tekst naar ondertitels
Het is fijn dat een robot je transcript automatisch omzet naar tekst. Maar met een hoop tekst op zich kan je nog niet zoveel doen. Vaak wil je het resultaat efficiënt kunnen nakijken, bewerken waar nodig en downloaden voor verder gebruik. Om een duidelijke formattering van sprekers en tijdscodes mogelijk te maken, moet het systeem op de achtergrond bijhouden welk woord op welk exact moment is gezegd, en wie dat zei. Scribewave heeft dit allemaal onder de motorkap, wat betekent dat je efficiënt kan bewerken en snel door het transcript kan gaan. Spraak en tekst zijn gelinkt aan elkaar, dus alles scrollt automatisch mee met de opname.
Tevreden van het resultaat? Dan kan je dit downloaden als Word document, exporteren naar Google docs, of er ondertitels van maken. Nog veel meer bestandsformaten zijn beschikbaar natuurlijk, elks met talloze opties, zoals het maximum aantal karakters (CPL) voor ondertitels.
Bestandsgrootte en duurtijd
Sommige tools en APIs komen met serieuze limitaties. Zo is de Whisper API van OpenAI beperkt tot bestanden van 20MB, wat erg klein is, zeker als je video uploadt. Om rond deze limieten te komen, kan je batching strategieën toepassen, maar deze maken het vaak moeilijk om de sprekers consistent te labelen, waardoor je twee parallelle processen nodig hebt. Sommige APIs ondersteunen enkel bepaalde bestandsformaten, waardoor je bestanden moet converteren tot mp3 of mp4 om er gebruik van te kunnen maken. Je kan het comprimeren en converteren ook gewoon skippen en van onbeperkte uploads gebruik maken op Scribewave. Ik was zelf zo gefrustreerd door het conversieproces en bestandslimieten op andere transcriptiediensten, dat ik een universeel upload- en verwerkingsmechanisme heb ingebouwd dat alle audio- en videobestanden tot 5GB en 10 uur duurtijd ondersteunt.
Conclusie: Transcriptie als hefboom voor inclusieve AI
Transcriptie mag dan een technisch nichedomein lijken, ik geloof dat het een cruciale schakel is in de grotere AI-keten. Gesproken taal vormt de basis van menselijke communicatie, en wie erin slaagt die communicatie accuraat, efficiënt en taalbewust om te zetten in tekst, opent de deur naar betere doorzoekbaarheid, toegankelijkheid, analyse en interactie met AI-systemen. Lokale talen en dialecten verdienen daarin een volwaardige plek, net als de mensen die ze spreken. Mijn missie met Scribewave is dan ook niet enkel om transcriptie toegankelijk te maken voor iedereen, maar vooral om ze slimmer, menselijker en beter afgestemd te maken op de realiteit van gebruikers buiten de Angelsaksische bubbel. Of je nu werkt aan een doctoraat, een documentaire, een vergadering of een meertalige rechtszaak; jouw woorden doen ertoe. En het is tijd dat je automatische transcriptietool dat ook weerspiegelt.
Over de auteur
Ulysse Maes
In een wereld waar Ulysse niet sterker kan zijn dan The Rock of charmanter dan Timothée Chalamet, triomfeert hij als het meesterbrein achter Scribewave. Hij verdedigt zo fier zijn troon als de koning van de nerds in "'t Stad", Antwerpen, België.
Gerelateerde artikelen
Ontdek meer artikelen over transcriptie, ondertiteling en vertaling

